
前言
常见的Jenkins持续交付管道是基于Build Pipeline View插件的,实际上是通过另外新建一个视图来将原本没有关系的Job串联在一起,构成“管道”视图。这种方式的好处在于实现简单,不需要变更使用习惯。
但是随着持续交付管道应用的深入,渐渐会发现这种方式的种种弊端:
与“管道流”的初衷违背。由于各个交付节点实际上是各自分离的独立Job,所以每一个Job会在都是在自己的独立工作空间进行构建任务。这与“管道流”的初衷-上一节点的合格交付物流入下一节点-是违背的,因为各个Job的交付物其实是没有直接关联的;
Job维护工作量大。由于每一个交付管道的节点数众多,意味着每一条交付管道需要你维护多个Job,然后再将各个Job串联。因此,你可能需要花费大量时间来维护多个Job配置;
交付反馈流程可能存在冗余。由于各个Job都有自己独立的工作空间,各个工作空间是无法直接交互的。为了尽早反馈,我们希望将反馈节点尽量分割开,比如单元测试和静态扫描我们会分离成两个Job,但是静态扫描实际会依赖单元测试的产物(主要是覆盖率jacoco文件),所以导致单元测试可能会在单元测试和静态扫描环节重复执行,同样的情况还存在于编译打包和部署环节。
因此,我们适时考虑Jenkins官方推荐的Pipeline As Code。
Jenkins的Pipeline As Code示例
熟悉Travis CI或GitLab CI的同事会发现,他们的持续集成与Jenkins的持续集成非常不一样。Travis CI和GitLab CI都依赖自己的配置文件(Travis是yaml,GitLab是yml)来实现持续交付管道,这就是Pipeline As Code的实现。
Jenkins的2.0版本号称是最大的一次变革,最主要也是因为开始支持Pipeline As Code来定义持续交付流程了。下面,我们会以实例来介绍Jenkins的Pipeline As Code。
首先,Jenkins的Pipeline As Code也是基于Jenkins的插件-Pipeline(关于这点笔者有话说,Jenkins的插件机制使得Jenkins的功能增强非常方便,但是同时业界也不少人担心陷入“插件地狱”,所以奉劝各位尽量少装插件,后面介绍基于Docker的持续交付方案中也会介绍如何避免装各种插件)。
在安装好Jenkins的Pipeline插件之后,在新建页面就能看到Pipeline选项了。
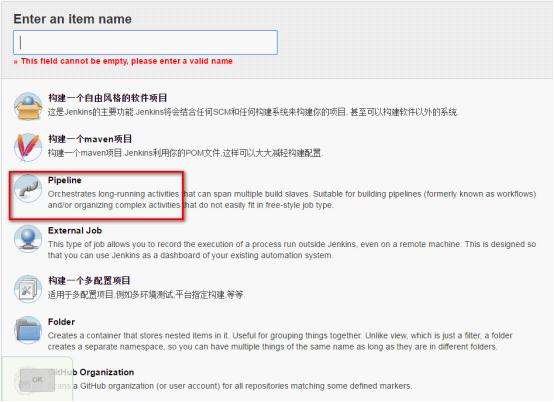
新建Pipeline之后进入配置页面,会发现里面少了很多常规配置项,主要内容只有一个Pipeline Script,这里的Pipeline Script就是你的Pipeline脚本。
下拉选择示例脚本,Github+Maven:
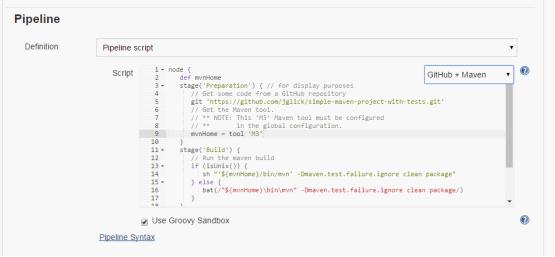
我们一行一行看一下含义:
第一行node:代表后面跟的大括号里的构建脚本将在哪个节点上运行,如果是空,则默认在master节点,否则可以写做node(“slave”),这里的slave是你的节点名称。
def mvnHome:定义一个变量mvnHome,因为Jenkins的Pipeline脚本是基于Groovy语言的,所以里面可以直接使用Groovy的一些语言特性,包括这里的定义变量以及后面的逻辑语句。
stage(‘Preparation’):定义一个交付节点,代表后面跟的大括号里的脚本统一定义为一个交付节点,节点名称为“Preparation”,有点类似之前方案中的持续交付管道的Job名称。
git ‘https://github.com/jglick/simple-maven-project-with-tests.git':获取指定git版本库的代码。这种格式是如何定义的呢?可以通过下方的Pipeline Syntax链接跳转到新页面进行调试。
例如如果希望获取某个git库的代码,选择git后填写好相应信息,点击Generate Pipeline Script,就会生成对应代码:
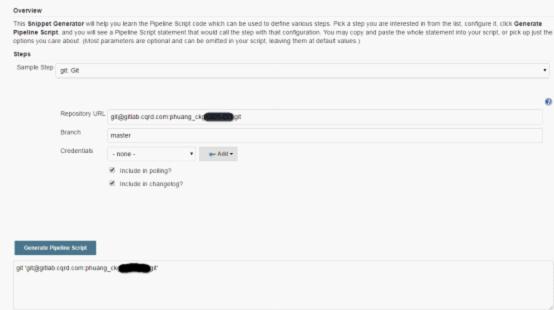
上面的例子不用输入git用户名密码,是因为配置了git的SSH Key。可参考:http://blog.csdn.net/fenglailea/article/details/39317513。
- mvnHome = tool ‘M3’:变量赋值。M3是哪里配置的呢?在装好Maven插件之后,系统管理里增加Maven时的命令。如下图:

“M3”就应该替换成“apache-maven-3.3.9”。
stage(‘Build’):定义另一个交付节点,代表后面跟的大括号里的脚本统一定义为一个交付节点,节点名称为“Build”。
if (isUnix()):判断服务器是否为Unix系列,与后面的大括号共同形成逻辑判断语句。
sh “‘${mvnHome}/bin/mvn’ -Dmaven.test.failure.ignore clean package”:如果服务器为Unix系列,则执行这段bash,${mvnHome}为前面定义的变量mvnHome的值。
bat(/“${mvnHome}\bin\mvn” -Dmaven.test.failure.ignore clean package/):如果服务器不为Unix(即为Windows系列),则执行这段bat。
stage(‘Results’):定义另一个交付节点,代表后面跟的大括号里的脚本统一定义为一个交付节点,节点名称为“’Results’”。
junit ‘*/target/surefire-reports/TEST-.xml’:发布junit测试结果,后面为junit执行产生的xml文件地址。
archive ‘target/*.jar’:存档文件,后面内容为存档文件路径。
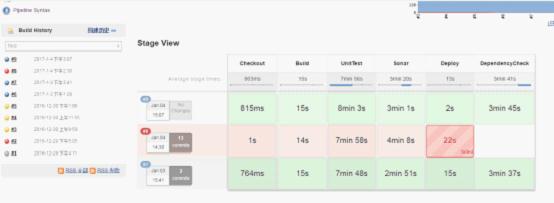
Pipeline的执行效果如下图所示:
Pipeline As Code的优势
从上面的示例脚本可以看出来,Build节点的产物如Jar包在最后的Result节点就可以直接存档了。这与管道流的概念不谋而合,下一个节点的产物应该来自于上一个节点。
以上示例脚本相当于完成了3个Job,所以维护工作相比之前的方式大大减少了。
由于整个管道都是在同一个工作空间,所以各个交付节点的产物都可以复用。之前存在的单元测试需要执行两遍的冗余就不存在了。
目前有个项目已经将传统的管道改成了Pipeline As Code的方式,完整的代码检出,编译打包,单元测试,静态扫描,依赖检查,测试环境部署整条管道花费15分钟以内,相比之前的方式(30分钟)整整节约了一倍时间。
扩展
随着软件行业的发展,越来越重视团队的整体性,不管是开发、测试、运维,都应该围绕共同目标努力,共同目标就是交付满足客户需求的成果。Jenkins的Pipeline As Code也支持从版本库中读取管道脚本文件。
这意味着项目团队可以把管道脚本文件和项目的其他配置文件一样纳入版本控制系统统一管理。这其实也对应了团队的整体性。通过这种方式团队可以非常自如地定义自己的持续交付管道,同时也降低了对持续集成环境的高度依赖,以前新增一个管道需要新增各个Job,然后再各个Job进行配置,配置的工作通常由中心的持续集成环境运维人员来完成或由项目组指定的持续集成环境运维人员来完成,而把管道用脚本文件来实现并纳入版本控制,团队成员都有职责来确保脚本的正确性。
敏捷、DevOps、Docker等各种概念都强调团队共同交付一个整体,包括软件代码、运行环境以及交付过程中的一些依赖配置。后续介绍基于Docker和PaaS的Pipeline As Code也会印证这一目标。